CyidaSubstrate 的核心功能就是提供了一个强大的注入功能
Cydia Substrate - Powerful Code Insertion Platform
– Cydia Substrate 源代码注释
其中提供了两个核心的 Hook 函数
MSHookMessageEx– 用于 hook Objective-C 方法MSHookFunction– 用于 hook C 语言函数
但是还有一个上次提到的 MSHookProcess,但是这个并不是属于公开的部分,但是也是做了 hook 工作。
MSHookProcess
这个是在上一篇说明启动原理时提到的一个注入 Cyida 就是利用了这个函数在系统启动时对 launchd 进行了注入。
这里先简单说一下结论:
函数利用了一些 mach 调用,在宿主进程的空间中分配了一些内存,然后将蹦床注入。
然后开启一个新的线程,执行蹦床的相应函数,引导目标动态库的加载,完成注入。
注入蹦床
注入蹦床的核心函数就在 MSHookProcess 中,函数原型为
|
|
函数首先通过下面的代码分配了一些栈空间以及和一个 Baton 数据结构。
|
|
接下来就是让 Baton 结构进入到宿主进程的空间中。这里是通过 mach 的系统调用完成,因为已经越狱,我们的程序是拥有 root 权限的,所以可以给其他进程发送 mach 消息。
|
|
这个时候已经将要加载的动态库信息放入了宿主空间中,然后就是让宿主去加载动态库了。这一切的实现都依赖于 mach 的进程远程调用,让这些实现成为可能。
因为程序的主线程正在执行它自己的工作,无法引导,所以这里就创建了一个新的线程,让注入的代码能跑起来,代码比较长,说明都在注释中了。
|
|
至此主要流程就已经结束了,剩下的则是监听这个线程是否是否消亡,保证程序执行完毕并且正确回收资源。
这个代码中依旧留下了一个疑点,即 Trampoline,这个跳板被注入到了程序中被执行,它做了什么?
跳板程序 Trampoline
之前的代码留下了一个 Trampoline_armv6_ 常量对象,而且关于这个跳板程序的文件有一下几个:
- Trampoline.hpp
- trampoline.sh
- Trampoline.t.cpp
头文件的内容很少,只定义了如下数据结构
|
|
包装了代码的数据以及大小、入口位置。
在 Trampoline.t.cpp 中的代码如下
|
|
线程执行的函数如下:
|
|
这些工作都是在宿主的进程空间中执行的,所以加载的动态库也属于宿主空间了。
至于 Trampoline_armv6_ 的生成,查看编译脚本有如下命令:
|
|
这个脚本的动作则是将 Trampoline.t.cpp 在不同的平台上编译好后,利用 lipo 查看目标文件的架构,对于每一个架构,利用 otool + sed + nm 分析 _Start 的入口点以及可执行段的位置和大小,生成对应的常量对象写到 Trampoline.t.hpp 中。所以可以看到,DarwinInjector.cpp 中有 #include "Trampoline.t.hpp"。
总结
所以,整个注入流程则是:
注入跳板 -> 远程创建线程执行跳板 -> 跳板开线程加载动态库
至此,进程注入的部分就分析的差不多了,可以看到 Mach 对程序的进程间远程调用的力量是如此强大让许多黑科技得到了实现。
MSHookFunction
这个函数实现了对 C/C++ 函数的 hook。也是 CydiaSubstrate 提供的基础功能之一。
同样这里也先放出其思路,其实也很简单:
修改函数的入口,先跳转到代替函数,对原来的函数入口做一个备份返回
函数原型
|
|
由上面的代码可以看出 MSHookFunction 其实是对 SubstrateHookFunction 的包装,后者根据不同的平台有不同的实现,因为代码是跑在手机上的,所以下面只摘取了 arm 部分的实现。
|
|
因为 ARM 指令有两种形式:ARM 指令和 Thumb 指令,对于不同的指令执行方式,Cyida使用了不同的 hook 方式。这里拿 ARM 指令方式的函数,即 SubstrateHookFunctionARM 来做分析。
ARM 指令注入
函数的原型如下:
|
|
包装调用是 process 为 NULL,内部代码中也没有使用到,symbol 则是要被 hook 的函数地址,replace 则是用于替代原函数的函数,result 则是被处理过的原函数的备份地址。具体为何如此设计,待我们分析慢慢道来。
备份指令
|
|
上面的函数获取了原函数的地址,并且取出了前两条 ARM 指令做为备份。
|
|
这里是在计算替换掉的两条指令需要用多少指令来进行还原。这个 for 循环其实值执行了两次,也就是查看了一下被替换的两条指令的情况。
核心检查在 A$pcrel$r(backup[offset]) 函数,这个函数定义如下:
|
|
看到这估计就会慌了,这究竟是个啥?这奇怪的函数名究竟是个啥?
这里就需要查询一下 ARM 的指令手册了,因为观察了一下调用是传进来的参数,是一条 ARM 机器指令,说明这里就是一个机器指令的检查。
ARM 指令格式
ARM 指令都是定长的,所有指令都是 32 位,占 4 个字节的空间。下面的表展示了 ARM 指令各个为代表的内容:
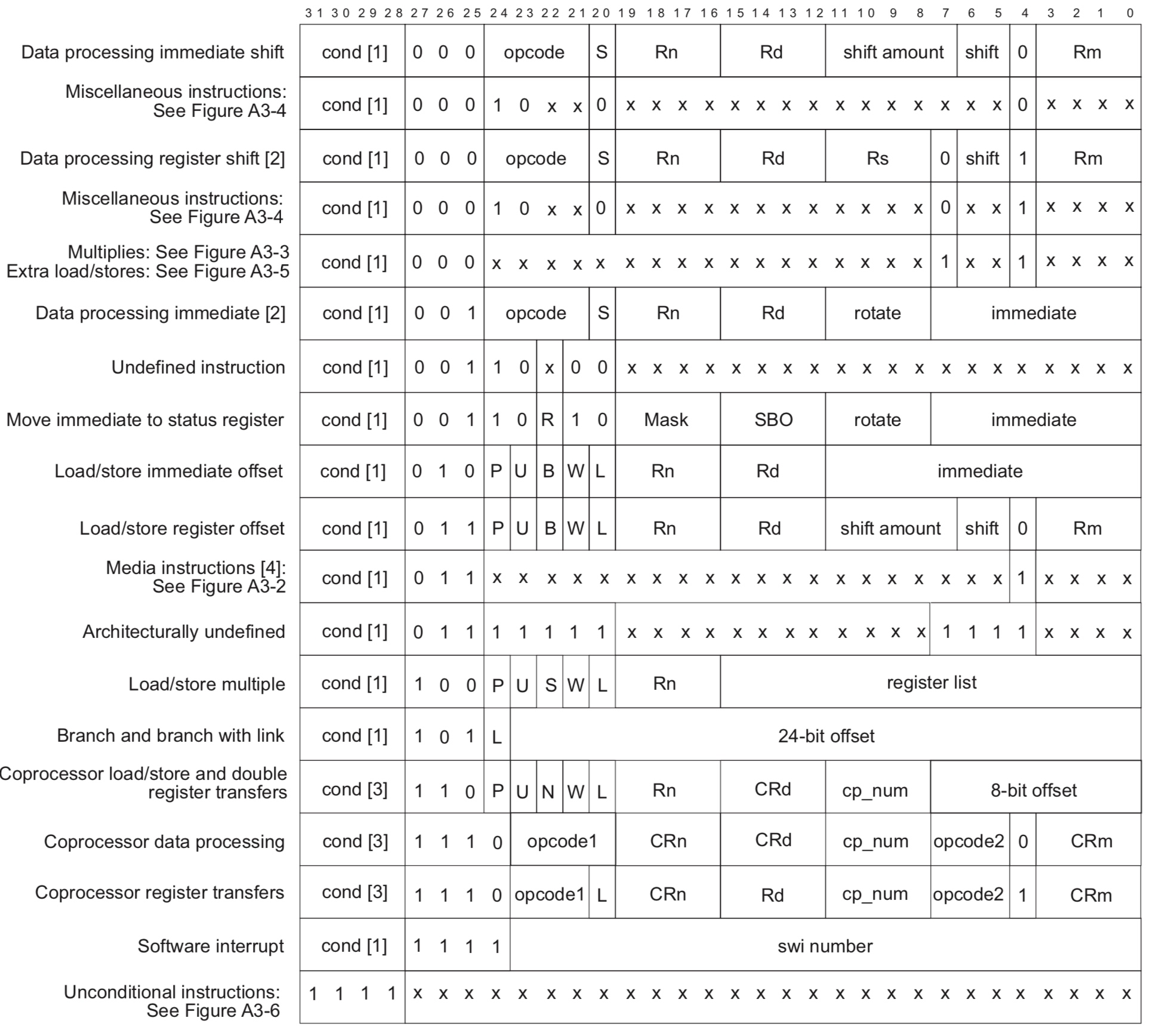
现在回顾函数的做的三个判断条件:
|
|
这些都是取出了某些位然后做出的检查判断。
第一个取出了指令的第 26~27 号位,这几位表示了指令的类型,检查这几位是否是 01。说明第一个是在检查指令是否是内存的读写指令。
第二个取出了指令的第 28~31 号位,并且希望它不是全 1,看到是不希望指令为无条件的指令。
第三个取出了指令的第 16~19 号位,即 Rn,表示源操作数,并且希望它为 0b1111,即寄存器 pc。
综合起来似乎就是判断这个指令是否是依赖 pc 来定位读写地址的指令。
回顾其函数名 A$pcrel$r A 就代表 ARM,中间的 pcrel 似乎就表着 pc relative。
但是为什么要做这种检查还不能太早下定论,需要进一步的探索才能了解。(当然,根据实现思路应该可以猜到是为什么了)
然后这个函数检查生效以后还有一个判断条件走不同的分支:
|
|
用和上面相同的办法进行查找,不过,因为第一个判断已经确定一个读写指令,所以可以对照读写指令的详细格式:


- I 指示指令的寻址方式,0 为立即数寻址,1 为寄存器寻址
第一个条件取出了指令的第 25 号位,判断是否为 0
第二个条件取出了指令的第 12~15 号位,并向右移 12 为,与第 0~4 号位进行比较,即比较Rd 与 Rm 是否相同。
这个条件则在筛选相对 pc 立即数寻址,即 ldr rd, [pc, #im] 这类指令以及 ldr rd, [pc, rd] 这类指令。
这类指令只需要 2 个多余指令来做还原处理,其他的则需要 4 个指令处理。
填充指令
|
|
分配一块内存,存放新的执行代码。
接下来开始填充代码,源代码如下:(不要紧张,可以先简单阅读,找出一些关键点)
|
|
先忽略代码中指令调整的处理,从代码逻辑可以看出来,在最简单的情况下,这个程序对原程序作了如下图的调整:
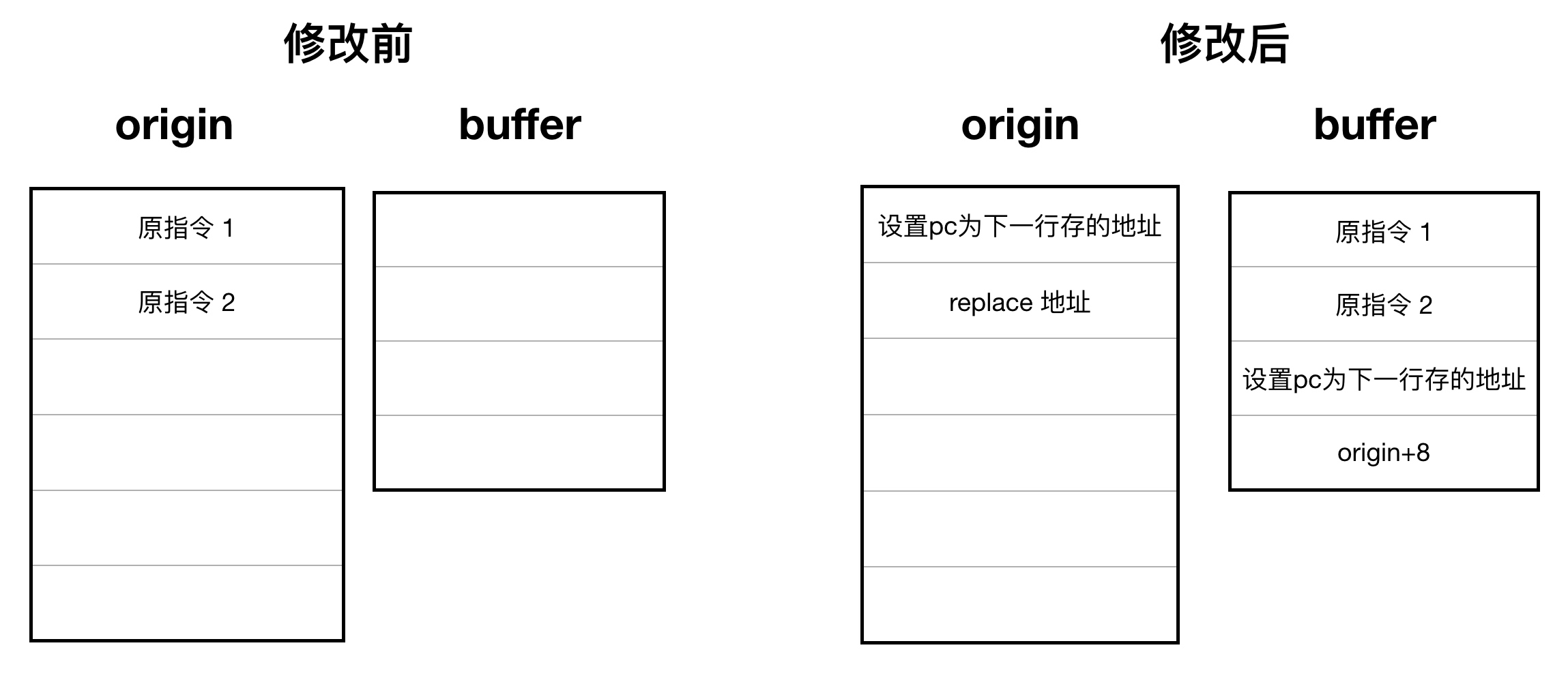
通过修改 pc 的值,就可以实现直接的跳转,如此实现的调用原函数会跳转到替代函数中,而想要调用原函数时,只需要对 buffer 进行调用,让它来帮助跳转即可,所以计算长度时最后多家的两个指令就是为了处理跳转使用。
至此,按理说 Cyida 对 C 语言的 hook 原理已经很清楚了,但是为什么还多出了这么多处理呢?
维护 pc 相对值
设想一下,如果原指令1、2都是类似 ldr rd, [pc, #im] 的指令,即读取相对于 pc 值某个偏移量的地址下的值。上图中的最简单版本会造成错误的结果。因为 buffer 的地址与 origin 的地址并不相同,所以执行到相应指令时 pc 值是不正确的。
所以,解决办法是就这一类指令进行单独的处理,恢复修改后造成的错误。
指令内容
为了不影响继续阅读,先解析一下源代码中出现的指令情况。
对于 ARM 指令,源代码中定义了很多指令在 ARM.happ 中,源代码如下:
|
|
这个文件定义了 ARM 的所有寄存器 r0~r15,不过关键是在还定义了许多宏,这些宏都代表了一条 ARM 指令。
这里拿出一个宏进行分析,其他的宏构造指令的方式都是一样的:
|
|
对照就可分析了:
|
|
判断 im 是否为负,为负则将 U 置为 0 表示要减掉,1 表示为加上。然后将 rn rd 移动到对应的位置,最后的部分放置立即数。
回到之前的讨论
源代码中做的指令检查就是为了筛选出这类指令,恢复的过程摘录如下:
|
|
这里依旧需要分成三种情况来讨论
指令为立即数偏移
指令为立即数偏移的情况来看,例如为如下指令:
|
|
经过上述的修改流程,可以知道 buffer 中的代码变成了如下形式:
|
|
假设只有第一行是需要特殊处理的,并且第一条形式跟现在讨论的相同,由上述推知 buffer 应该有 6 个指令长,操作过后buffer指令的形式如下:

这里需要说明一下为什么会有一个 -8 的操作。查询 ARM 的手册,有如下几句话:
For an ARM instruction, the value read is the address of the instruction plus 8 bytes. Bits [1:0] of this value are always zero, because ARM instructions are always word-aligned
写入的话就是正常操作。如此这般就恢复了原来应该 r8 写入的值。
注意最后的地址为 origin + 8 而不是 origin 是因为原来的指令中读出的 pc 值是加了 8 的,这里也需要进行恢复。
指令为寄存器偏移并且 rd 与 rm 不相同
这种情况生成的代码与上面的类似,依旧拿一个指令举例:
|
|
在前提跟上一中情况相同的情况下,buffer 中的代码只是第二条指令变成了
|
|
指令为寄存器偏移并且 rd 与 rm 相同
依旧举一个例子:
|
|
前提依旧跟第一种情况一样,不过现在 buffer 的长度为 8 条指令。
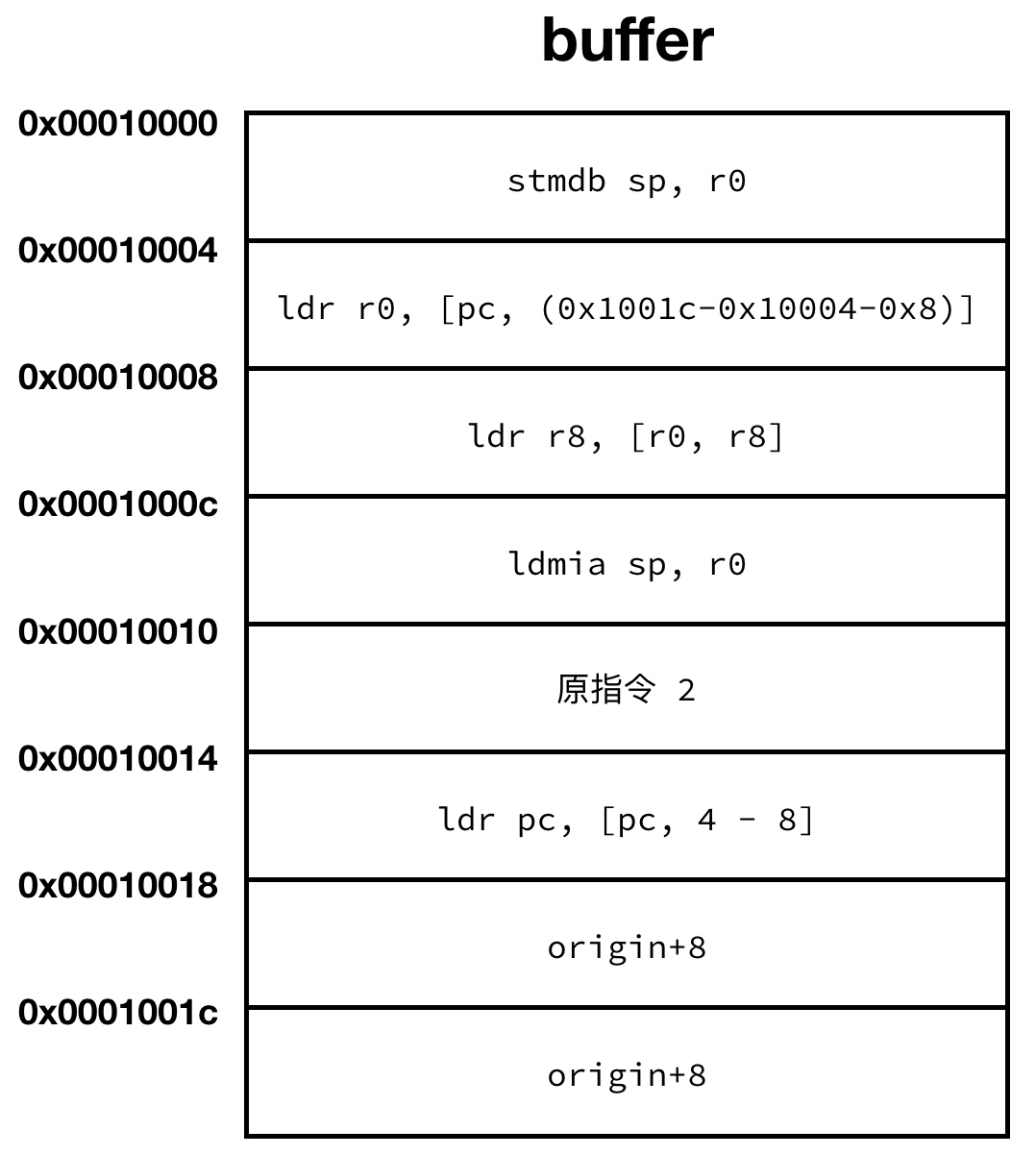
原理也很简单,因为这里需要一个中间变量 r0,但是又不能破坏原来 r0 中的值,所以使用栈暂时将 r0 的值进行保存。
只能 hook 一次
源代码在开始不久就有一个这样的检查,是不是很眼熟?这就是 hook 后修改的内存指令。这里检查函数是否被 hook 过了,如果被 hook 过了,就将 hook 的原 replace 函数作为结果返回,方便我们队之前的 hook 函数进行 hook。
|
|
总结
自此,SubstrateHookFunctionARM 函数就分析完毕了,其实还有一个 SubstrateHookFunctionThumb 函数,负责用来 hook Thmub 指令模式下的函数。
经过了这一系列的操作,调用顺序这变成了下面的形式:
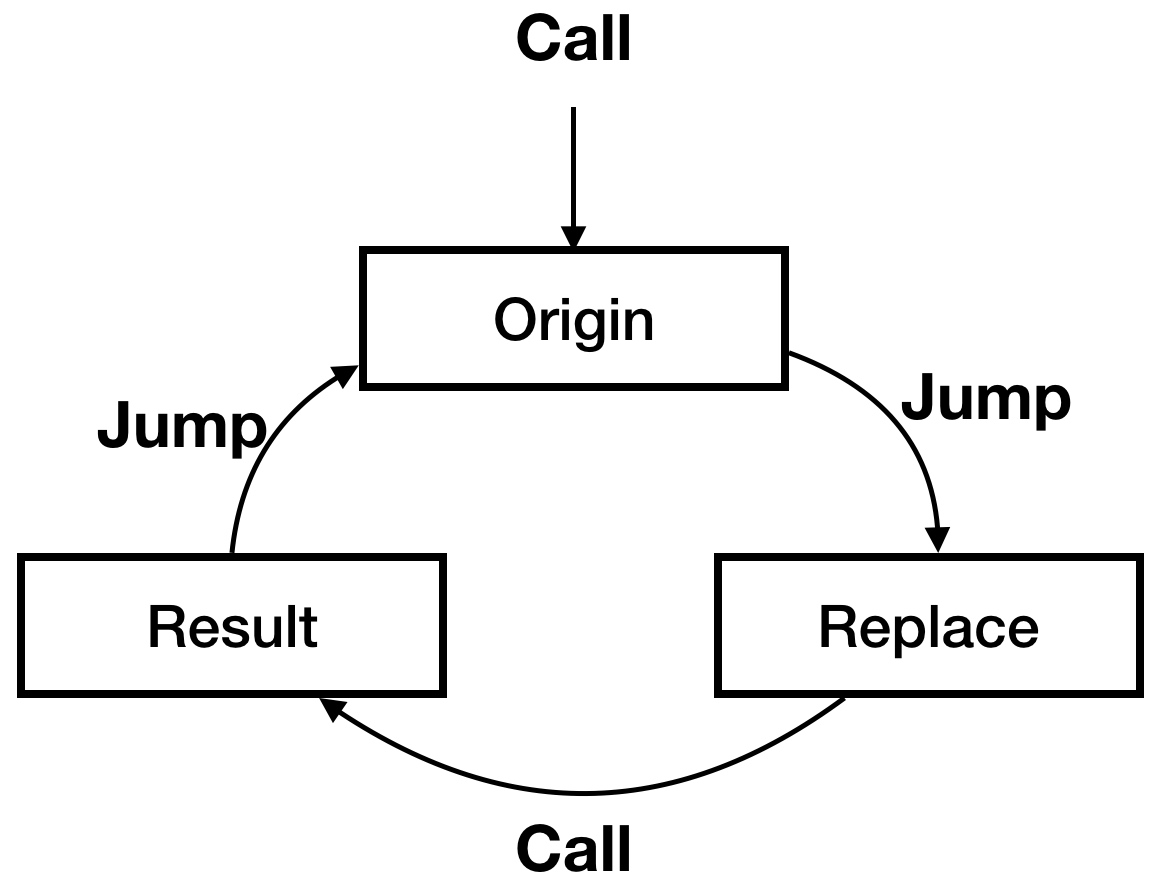
看上去似乎循环了,但是 Result 的跳转是到原函数的第3条指令,所以不会发生死循环。
MSHookMessage
在 arm 中,Cyida 提供了三个接口对 Objective-C 的方法进行 hook:
|
|
这三个函数都是对一个核心函数的包装,即:
|
|
几个参数分别是 目标类、目标方法,用于替换的方法实现、原函数的实现、原函数的重命名的前缀。
有了之前分析的经验,接下来的工作就会顺利很多,深吸一口气,开始吧!
HookInternal
首先代码先从继承链上拿到目标方法以及相关信息:
|
|
函数的实现如下:
|
|
接下来判断目标函数是不是继承过来的,这点可以先留着:
|
|
接下来根据 direct 的值有一个分支:
|
|
替换实现
然后就是核心的操作了,下面的注释基于假设方法是直属的假设进行分析的,利用了 Objective-C 的 runtime 技术:
|
|
将旧的实现返回以及使用新的名字将原来的函数放回方便调用,这是最基本的处理思路。
至此,主要的替换方式就已经明确,但是下面还将讨论一下细节。
!direct
接下来就是摘取看 !direct 分支究竟做了什么。这个前提是目标方法是继承而来的.
下面的代码只展示了 arm 部分的代码并且删除了一些 log 语句:
|
|
依旧对照根据之前的宏,可以将 buffer 中的内容翻译成如下的汇编代码:
|
|
这段代码是获取函数的父类的旧实现,然后跳转执行。此时 old 的实现变成了 buffer 这段代码。
在非直属方法的情况下,最后给本类添加新的同名方法,原函数的调用则返回了处理过后的 buffer。
|
|
为什么要做这个处理,参考 官方说明页面 提到:
However, while these APIs function quite well when there are only a small number of people making modifications, they fail to satisfy more complex use cases; in particular, there are ordering problems if multiple people attempt to hook the same message at different points in an inheritance hierarchy.
Finally, it is important that classes that are being instrumented are not “initialized” as they are being modified (which would both change the ordering of the target program, as well as make it impossible to hook the initialization sequence); over time, the way Objective-C runtime APIs implement this has changed.
Substrate solves all of these problems by providing a replacement API that takes all of these issues into account, always making certain that the classes are not initialized and that the right “next implementation” is used while walking back up an inheritance hierarchy.
这么做的目的是为了让继承链上的函数能得到正确的 next implementation 。
情景分析:
考虑如下的继承关系 A 类,B 类,C 类,继承关系为 C -> B -> A,现在 A 类有一个方法 method,并且 B、C 类都没有实现,即从 A 类继承的方法。
所有 hook 后的替换函数都调用了原函数以保证功能正确。
假设 C 先 hook,B 后 hook。
如果没有如此上面的处理,直接将父类的实现地址放到内存中,则会产生如下的调用链:
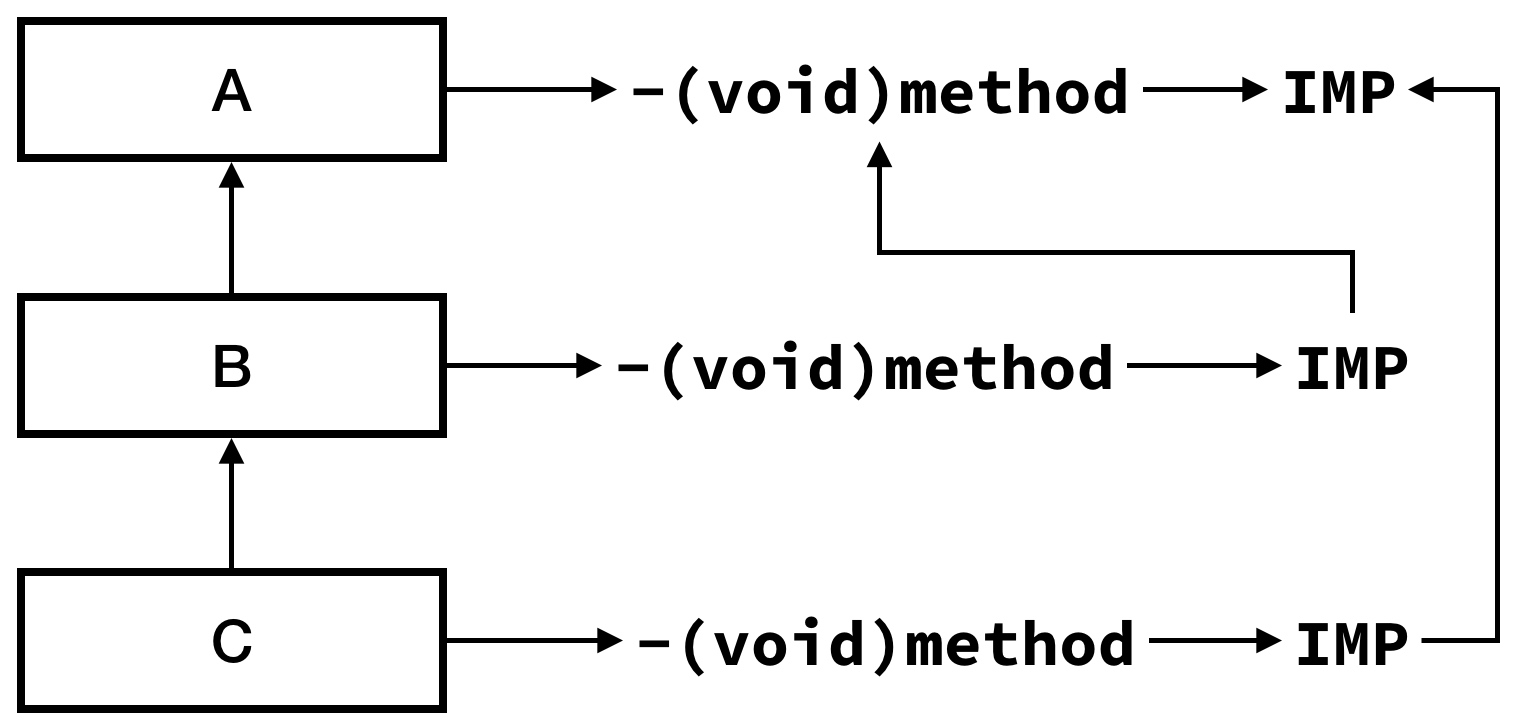
因为 B 的 method 后与 C 添加,所以在调用 [c method] 时不会运行 B 的自定义函数。
如果做了上述的处理,就可以动态的查询父类的实现,就能生成如下如下的调用链:
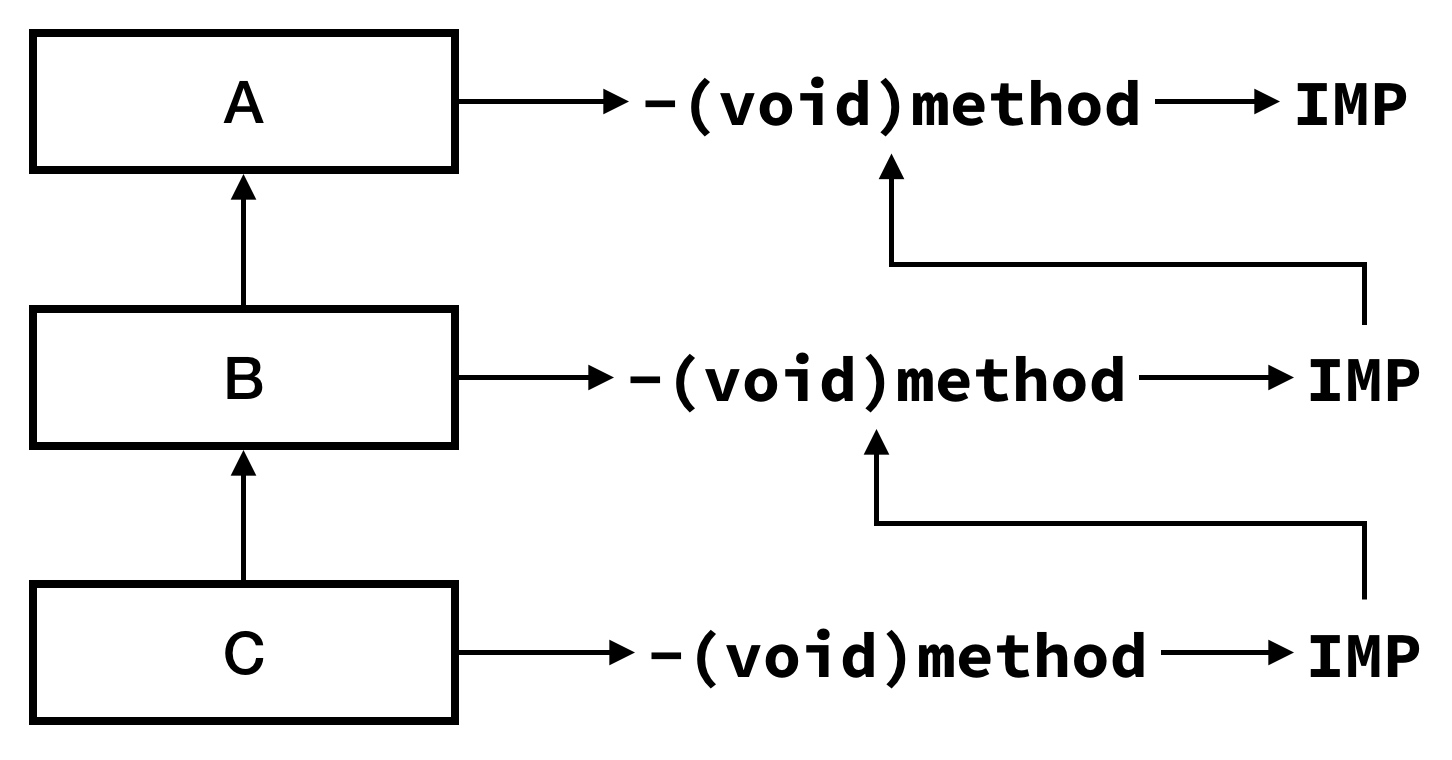
这样在调用 [c method] 时,B 的函数也能正确的被调用。使得调用的顺序与 hook 的顺序无关。
总结
OC 的 runtime 机制让 OC 方法的 hook 实现简单了很多,利用方法实现的替换就可以做到对方法的 hook。这里的精髓则是在 hook 时,对调用链进行的处理。
Summary
Cydia 提供了三个接口来进行 hook 工作,但是开放的只有后两个。这里充分体现了对函数 hook 的思想:
在程序入口做跳转,保存原来的函数地址。
Cydia 的实现,大都是修改了对应函数的部分内存,利用 mach 的一些系统调用来注入自己的代码。对 ARM 代码直接编码进行注入的方式也是比较精巧的。让人受益匪浅。
可惜的是这是一个老版本的源码,都是建立在 32 位的 ARM 汇编下做的处理。因为高版本的 Cydia 已经闭源,所以只能通过逆向的方式对其 hook 原理做探索了。但是老基本的思想应该是不变的。
只能说,是真的大牛,学到了。
参考资料
- Hook 原理之 CydiaSubstrate(一):MSHookMessageEx
- ARM Architecture Reference Manual