概览
上次我们讨论了最简单的一维线性方程的学习方法,但是大致的思路还是跟上一次很相像的,只不过这一次我们一次性要调整的参数更多、涉及的变量也比之前多一些,那么我们就准备开始吧。
公式形式
基本形式
我们的公式依旧是上篇提到的那一个:
其中 是一个 维的向量, 是一个 维的向量, 就理所当然应该是一个 维系数矩阵。具体形式如下:
所以我们要调整参数就是 个。
相应的:
就是我们模型要计算的东西,现在 中的每一个元素都与 中的每一个元素有关联。
损失函数
我们依旧使用上一篇我们提到的距离,但是现在不是一个元素之间的距离,我们现在要计算 中每一个元素与我们模型计算出来的 对应元素的距离之和,即两向量之间的距离.
即:
寻求梯度
因为真实的 和输入 是固定的,我们要调整的变量就是 中的所有元素。
要研究每一个变量对 的影响,我们先把 暴露出来:
现在式子开始变得有点恐怖了,这只是为了表示方便而写的式子。我们可以尝试让 对任取的一个 求导,比如我们选择 ,则有:
- 第一步的推导是我们发现,在对 求偏导时,求和符号, 除了 ,其他项并不包含 ,所以对它来说相当于常数,常数求导为 ,所以得第一个式子。
- 第二个式子发现距离只是绝对值,我们把它取出来。
- 第三个式子应用的原理与第一步是一样的,因为绝对值要分端求导,即可得结果。
我们就可以发现以下规律:
我们发现求导出来的式子很简单,然后我们把所有对 的偏导组合在一起成为一个矩阵,为了表示方便,我们将 表示成 ,则我们组合出下面这样的矩阵:
我们把上面这样对每个变量求偏导后形成的矩阵叫做雅克比( Jacobi )矩阵,上面的式子就是 的雅克比矩阵,我们就利用它来调整 矩阵。
我相信看这篇文章的人应该知道一个函数的梯度方向是其增大最快的方向,我们求出来的Jacobi矩阵就是我们梯度一种表示形式,只是之前的梯度是一行或一列的,这里是 的,如果把它展开成一列,也就成了平时看到的梯度的表示形式。
其实这种方法叫做梯度下降法,这种方法会在之后进行介绍。
学习
有了上面的认识,我们就可以用下面的式子来更新我们的 :
其中 是上篇提到的学习率。
代码流程
整个程序还是跟之前的训练流程是一样的。
|
|
设定我们要学习出来的参数:
|
|
生成训练用的数据 X,Y
|
|
我们用下面的函数来计算雅克比矩阵,正是应用了上面的公式
|
|
下面就是学习的过程
|
|
看看学习出来的
|
|
与我们设定的
|
|
已经足够接近了,如果我们把学习率调整得更低,训练的步数再适当调高,就可以得到更精确的值。
让我们看loss的变化情况
|
|
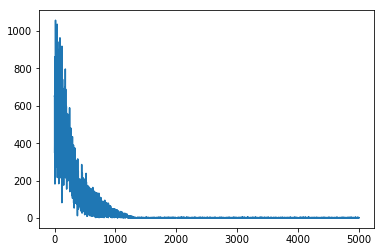
loss虽然有很多抖动,但是总体的趋势在不断减小的,最后趋向与0。
总结
这次我们看到了机器在进行学习多维线性方程的时候的表现,但是我们不禁会问,那么之前提到的形如:
的方程,如何才能学习到
其实我们可以做这样的转化:
在 的最后再添加一维,取值为 然后将 拼接到 的最后一列,即:
然后问题就转化到了本文讨论的问题。
虽然线性回归在机器学习以及深度学习中是比较简单的例子,但是在其中确有很大的应用,而且也可从线性回归简单的探寻到深度学习的基本工作流程。当然实际的深度学习机理要比这复杂的多,我也会在之后的学习中发表这一系列的文章。下一篇应该就是一些基本理论的介绍,不出意外应该也会一起展示的内容。