概述
本篇将分析Mnist手写识别的从数据准备到网络构建、调整参数的各个方面来展示深度学习的一个简单应用方法。
Mnist数据集
下面是Minst数据集的简介:
The MNIST database of handwritten digits, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image.
MNIST是NIST数据集的子集,它已经帮助我们把图片大小归一成一样的大小,并且数字一定摆在图像的中心。训练集有60000个样本,测试集有10000个样本。
数据准备
数据获取
我们可以到Mnist官网下载到数据集,数据集分成4个部分:
- train-images-idx3-ubyte.gz: 训练集图片 (9912422 bytes)
- train-labels-idx1-ubyte.gz: 训练集标签 (28881 bytes)
- t10k-images-idx3-ubyte.gz: 测试集图片 (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: 测试集标签 (4542 bytes)
我们将上面的4个文件放到./MNIST_data/文件夹下,方便之后的操作。
数据提取
我们先导入我们要用的工具包:
|
|
我们根据官网的对数据集的格式规定:
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| … | … | … | … |
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| … | … | … | … |
我们设计以下代码来提取文件中的数据:
|
|
这里涉及到一些
numpy的操作,如果有疑惑的地方请自行查阅相关的文档。
上面代码的总体思路就是给定的格式将文件中的数据一个一个读取出来,图片数据就是一行28x28个整型数据,范围是0~255。最后我们调用函数将数据读出。
其中有一个比较有意思的操作是在将标签转化成one-hot向量的时候运用的技巧,算出每一个标签在数组中的其实偏移量,即index_offset,让后将目标的数据铺平后给给每个标签的位置赋值为一,即label_data.flat[index_offset+labels] = 1,这样的操作要比循环读取的速度快很多。
这段代码参考了tensorflow官方mnist教程的读取代码
为了减小每一步我们的计算量,我们将训练集用以下的生成器来将数据集分割成一定大小的分块(batch)
|
|
让我们把读取的数据取一部分出来看看吧:
|
|
以下是输出:
|
|

从数据和图片不难看出one-hot编码的含义,就是数字0~9,是哪一个数字就在那一位上置1,其余都是0。从概率分布的角度来看,这就是一个Multinoulli分布,在这个位置的概率为1,依据概率分布的归一性,所以其余的位置都是0.
网络构建
我们这次的网络结构非常简单,目的有几个,一个是容易理解,二是可以在我们力所能及的范围内演示一遍运算层与层之间的运用链式链式法则求导。
网络结构
转变成数学符号,就是:
上面的公式就是我们的模型,一个全连接层加上一个 输出层,其中下标表示矩阵的维数,问号表示这一维的长度不定,例如 表示有很多行的数据,每一行是一幅被以行优先的方式展开的图像的像素值。
因为输出的是一个概率模型,所以我们选择用交叉熵作为代价函数,调整参数,所以我们的 的函数表达式如下:
其中 是传入的标签one-hot向量。
外层的求和是求平均值,内层求和是求一行的交叉熵, 是一次性输入网络的图片的个数。
梯度计算
这一部分才是本篇的重点,但是你对这部分数学推导实在是没有兴趣,可以选择跳过,因为下面的内容在实际的应用中并不会出现,都是被别人包装好了的,但是为了能更好的理解,我选择在这里将过程全部展现。
我们尝试自己推导一下 对 , 的 矩阵,即梯度。
求这两个梯度要用到多维函数求导和链式法则,这里做一个简单的复习:
设有一下两个函数:
我们要求各个 对 的偏导,则有如下推导式:
我们把上面的式子用矩阵的方式表示,则有:
即:
如果你上面的推导不能勾起你对微积分求导时的记忆,可能你就得需要回去看看书了解一下偏导的含义了。
下面我们来看一下 的函数组成:
注意上面的式子各个变量的维数。
则我们一步一步的尝试求导:
对于 , 是一个 的矩阵,设矩阵下标为 则:
对于 则比较特殊,因为 是一个 的矩阵,但是对于每一个 我们要求出对矩阵 的每一个都做一次偏导,我们先将 展开成一个 的向量,然后对其进行求导。因为 是一个线性函数,所以求导就比较简单,但求出来的 是一个 的矩阵。
从矩阵运算法则可以知道 只与 有关,为了方便操作这种性质,我们把 的维度改成 ,设各维的下标为 则:
最后将其维数变回来就行。
就很简单了,一个 的矩阵,每个元素都是 。
最后:
这里没有用到 如果我们有更多的参数层的话,我们就需要用这个中间量传递到下一层来求对下一层的梯度。
梯度代码
终于把梯度求完了,让我们看看代码是怎么写的吧(其实就是对上面的公式进行应用):
|
|
模型训练
训练代码
设定一些超参数以及初始化参数:
|
|
开始训练,训练的步骤依然跟以前一样,获取数据,求 ,求解梯度,然后调整参数,不断循环:
|
|
loss 的变化
用一下代码将 的变化情况输出:
|
|
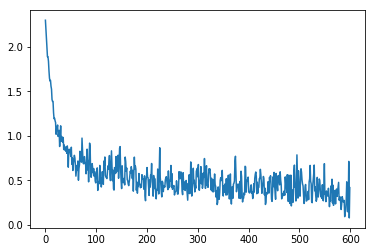
我们可以很好的看出 的下降趋势,说明我们的训练还是很有效果的。
模型检验
最后我们要在测试集上看看我们的模型表现的怎么样,也就是计算一下模型识别的准确率如何。
我们用以下代码进行计算:
|
|
上面的代码的输出如下:
|
|
说明我们的模型在测试集上的有 90.04% 的准确率,识别率已经很高了。这进一步说明了我们的模型训练是有成效的。
总结
本篇的篇幅比较长,我们利用Mnist数据集进行了一次识别的演练,整个过程我们体会了深度学习从数据准备,模型的准备,调参的原理实践到观察模型变化,验证模型的整个过程,我想应该对深度学习有了更深一点的理解。
我们花了很大的篇幅在讲求导的过程,但实际上利用链式法则求导的过程在我们使用深度学习计算库的时候,他们都已经给我们做好了便捷的包装,多数我们只需要设定一下就好,而且计算效率要比我们上面的代码效率高得多。
上面的代码运行可能需要一些时间,代码都是顺序给出的,可以直接粘贴进行使用,只需安装相应的包即可,求导的计算过程可能会花费比较多的时间。如果有更高效的求法希望能指出,我个人的建议还是调用深度学习库比较稳妥,因为有比较成熟的优化。